







Blog
Website adjustment to the new design
When we discuss the image archive and explain features such as searching or creating image collections in more detail, we are always referring to the actual application within prometheus: pandora. However, our online offering consists of two parts, and the second part is our website. A few years ago, we decided against using a large content management system (CMS), which would have to execute a large amount of code and make database queries for every page view. A system like that isn’t necessary for our needs, so it wouldn’t be particularly efficient, and it’s also prone to errors and security vulnerabilities. Instead, we generate the website using Jekyll, a software program written in Ruby. Jekyll allows us to create static HTML web pages using simple text files. The content and layout files are read in and define the text and design.
We have now updated these pages to match the new design as well. The navigation menu is now located in the top right corner as a “hamburger menu”, which you can expand and collapse to view all the menu items that were previously available.
Image database updates
The number of images available for your research in prometheus is constantly growing. This is either because we are able to integrate a new image database or, more commonly, because we are updating the existing databases. During an update, newly added records are indexed, or changes to existing records are incorporated into the index, ensuring that the search engine in prometheus contains accurate and up-to-date data.

A recent example is the Maya Image Archive at the University of Bonn’s Department of Ancient American Studies, a research center affiliated with the North Rhine-Westphalia Academy of Sciences and Arts. As of this week, 19.982 records from the research database are available—records from image collections containing photographs, drawings, notes, and manuscripts that allow users to search through the results of several decades of research expeditions throughout the entire Maya region.

New planned features
We are currently planning the next implementations of new features for the image archive.

- “Autocomplete” for search terms: automatically completing your input in the search field as you type, to save time and simplify usage.
- “Faceted Search” as a filtering method: search results can be specifically combined and narrowed down using predefined attributes (facets).
- display “Search History”

- “Multiple File Upload” in own image databases.

- “Pinboard” for questions from the community, for example: “Can anyone help me? I’m looking for a rear view of the Albertus Magnus statue by the artist Gerhard Marcks, which stands in front of the main building of the University of Cologne."
All features will be implemented—the only question is when: Which of the functions should we implement first? What order would you prefer? Please drop us a quick note with your preferred order, either via email or using the feedback form. We look forward to hearing about your preferences.
Zoom in on thumbnails
To help you avoid having to click on every image in your search results to decide whether it’s suitable, and to allow you to narrow down your options more effectively, a zoom feature is available.

When this feature is turned on, you’ll see a magnified view while you hover your mouse over the image.

You can turn this feature on or off in the list view of your search results (which displays basic image metadata), in the gallery view with thumbnails, as well as in image collections, your favorites, and your uploads.
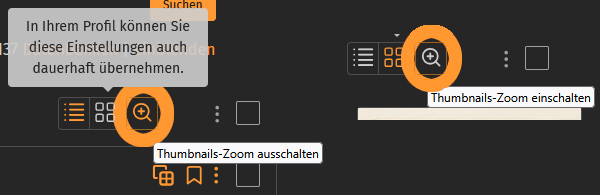
If you prefer to work with or without zoom, you don’t have to turn it on or off for each view; instead, you can set it by checking the box under “zoom thumbnails” in your settings. You also have this option there for image collection entries, uploads, and favorites.
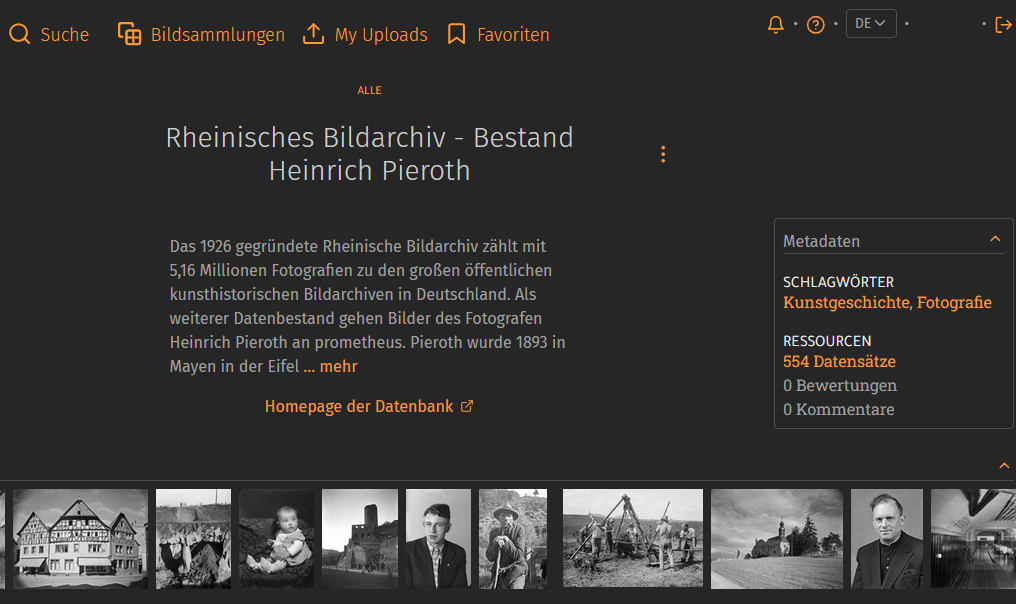
Heinrich Pieroth Collection
Another research database from the Rheinish Image Archive has been added to the site in the past few days.
With 5.16 million photographs, the Rheinish Image Archive, founded in 1926, ranks among the largest public art-historical image archives in Germany. This collection includes the estate of photographer Heinrich Pieroth, who was born in Mayen in the Eifel region in 1893. For more than five decades, he ran a photography studio in his hometown and dedicated his entire photographic oeuvre to the Vulkaneifel. From 1920 through the 1950s, he explored the cultural landscape and its buildings with his camera. He found his subjects in the villages, as well as in the fields and quarries: people going about their daily work and enjoying their cultural pastimes. Pieroth’s photographs are visual records of life in the Vulkaneifel during the last century.
“Rhenish Image Archive – Heinrich Pieroth Collection”
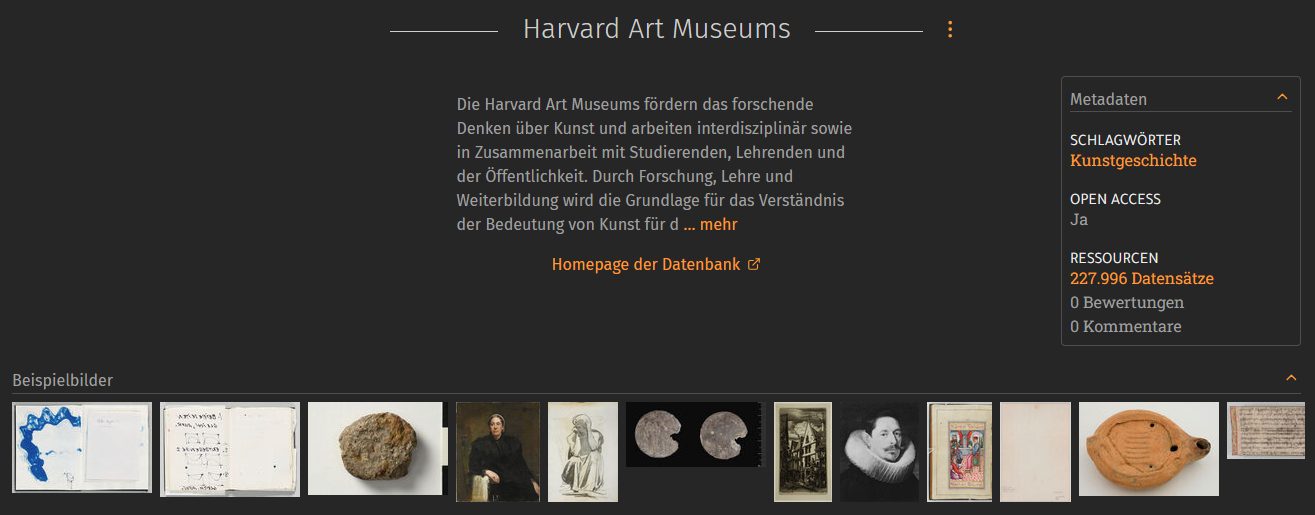
Over 4 million
As of yesterday, the image archive has surpassed another million-mark milestone. With the integration of an additional image database, we now offer you over 4 million records for your research. The Harvard Art Museums, which include the Fogg, Busch-Reisinger, and Arthur M. Sackler museums in Cambridge, USA, offer a wide range of artworks from various eras and regions through their online collections. Examples from the 227,996 records …
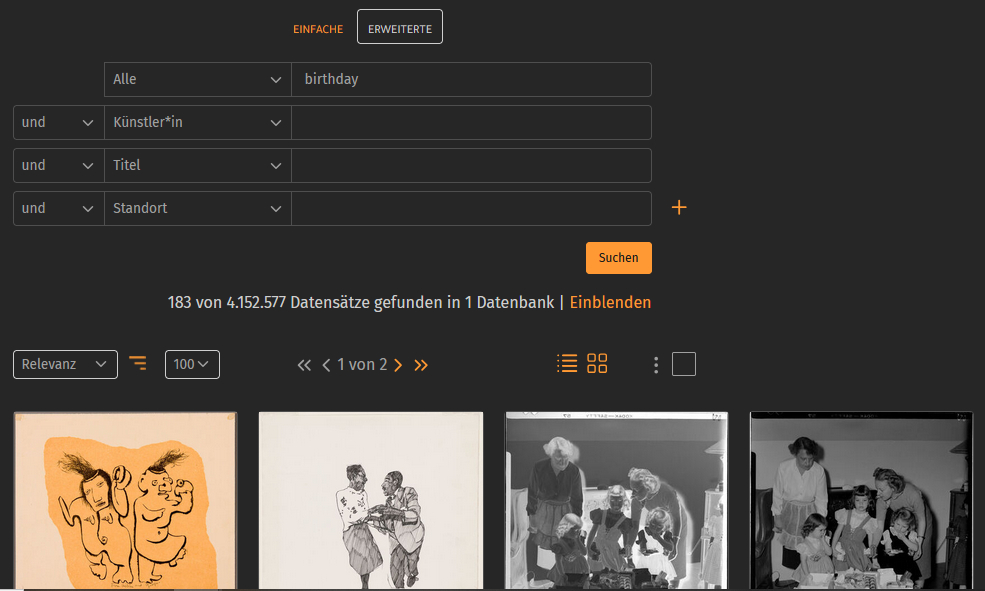
…searching for “birthday”…
Have fun browsing!
Customize ...
If you have a personal account with prometheus, you can edit your profile and set your personal preferences by clicking on your name. How do you prefer to work in the image archive? Would you like to start with the basic search or the advanced search? Do you prefer the gallery view or the list view? Do you prefer to view 20 or 100 records per page? Which sorting option do you prefer—by title, artist, or another criterion?

Changing the settings alters the display of the search results.

Of course, you can always change these custom settings directly without having to modify the default settings each time.

Searching the image archive. Simple and more
prometheus offers two different search options. With the simple search you can quickly and easily search for your search terms across all fields. The advanced search allows you to search specific fields such as artist and title. In addition, there are various options in both searches for searching for images more specifically. If you search across all fields using the simple search, you can further refine your search using the search syntax. Use wildcards to find images for imprecise terms. These wildcards include * (*wurm), ? (pi?asso), and ~ (Gaugun~).
The advanced search allows you to combine different fields. For example, you can search for artist and genre:

A link is created here using the Boolean operators “and” and “or”:

Why not give it a try with “and not”.
Favorite image collections and datasets
Previously, your favorites were on the left side, but now you can select your favorites in the top bar next to Search, Image Collections, and My Uploads:

As before, you can add individual images or entire image collections to your favorites. The selection process is easier: simply click on the corresponding icon in the respective data record …
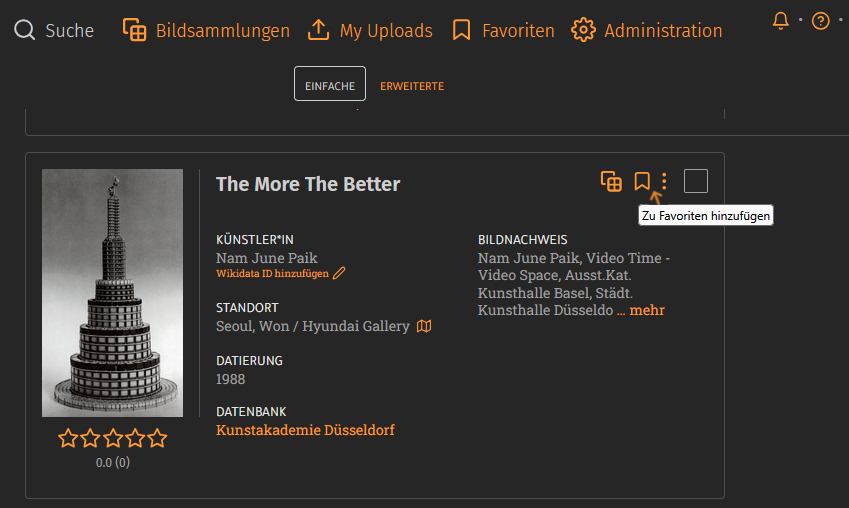
… or click on it again to remove the record from your favorites overview.
Delete images in your image collections
Until now it wasn’t possible to select multiple images in one of your image collections to then delete all of them in one step.

It is possible now. Click on the three dots and you can choose between “Add records to collection” and “Remove records from collection”.

This only applies to your own image collections or to image collections you were invited to for collaboration. Public collections, either readable or writable, are excluded.