








Blog

Shibboleth (DFN-AAI) is a national browser-based infrastructure that was developed to provide a simple, transparent and secure process that can be used to shorten and streamline the authentication of people and the granting of authorizations. You only need to log in at one location (single sign-on), for example at your home university, and you can then access many different licensed services and online publications. It does not matter which device you use.
prometheus cannot yet be used via Shibboleth. The emphasis is on “not yet” because we are currently testing intensively with some institutions such as the University of Cologne. Here, logging in from outside already works for the test group:
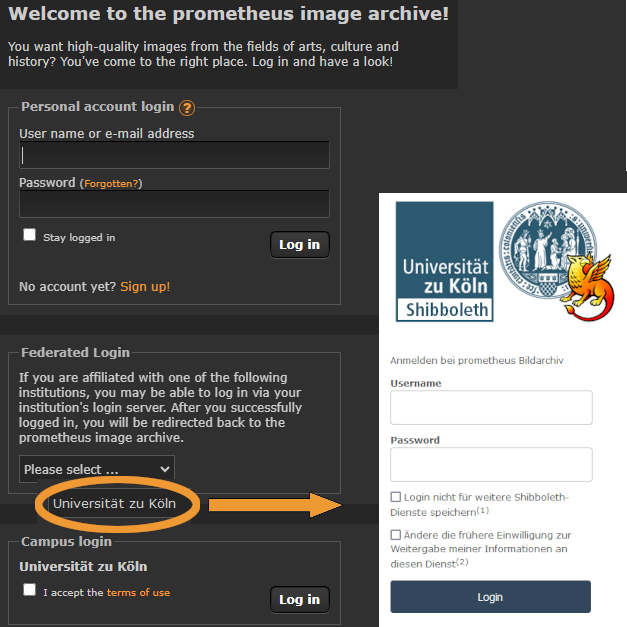
Additional interested licensed institutions will be gradually integrated. If you are interested, please contact us.
… and further steps will be implemented in the next few weeks, for example the integration of your personal access with settings, personal data, image collections and image uploads, even if you change institutes.
The collaborative platform ARTigo, a long-term project of the Ludwig Maximilian University of Munich, brings together many game variants, all of which work in such a way that reproductions of works of art shown are to be tagged with keywords within a certain time in order to score as many points as possible as a player. After the games, these keywords are visible and saved as metadata for the images. This is intended to improve searches for works of art in image databases. In prometheus, the tags generated in this way are integrated into two image databases, one in DadaWeb from the Art History Institute of the University of Cologne and the other in ArteMIS, the original database of the Art History Institute of the Ludwig Maximilian University of Munich. As the following example shows, this metadata is also used to find “Bonaparte franchissant les Alpes au Grand-Saint-Bernard | Bonaparte crosses the Saint Bernard Pass” by Jacques Louis David…
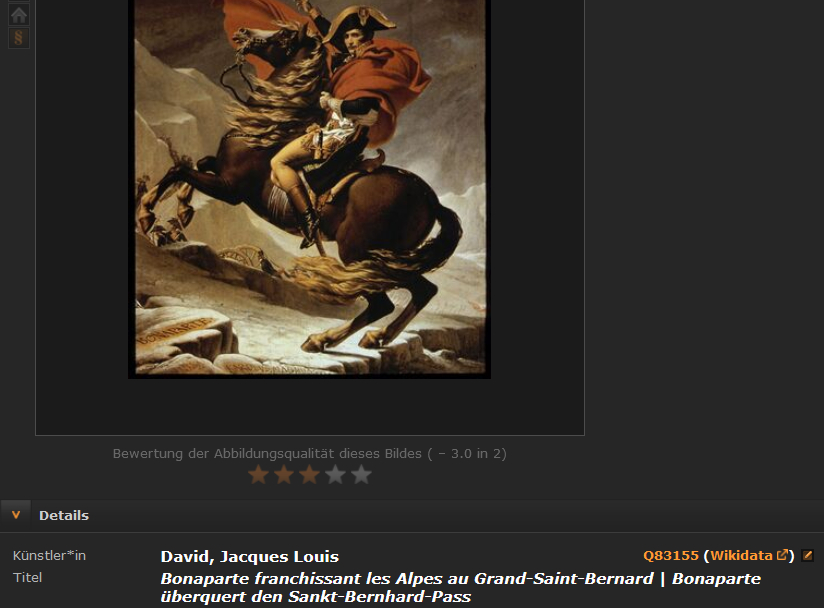
…under the search term “Napoleon”.

For some searches, it may be useful not to search with the additional keywords. Therefore, in prometheus’ advanced search, it is possible to search across all fields and across all fields including the ARTigo tags.
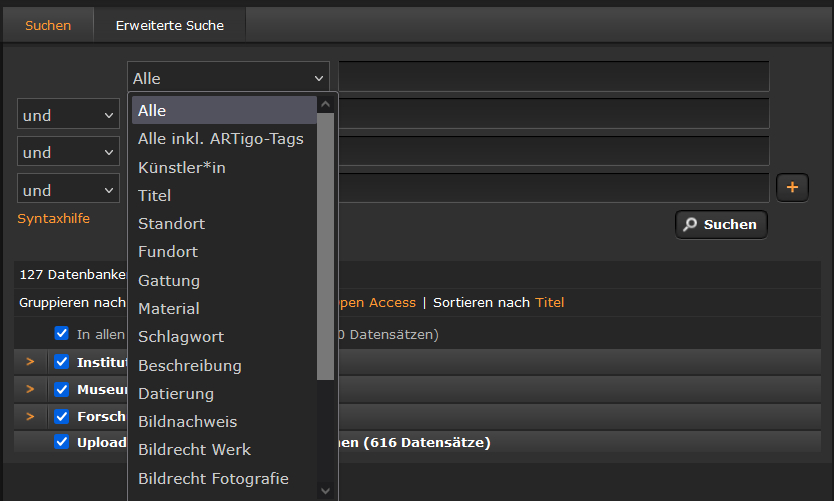
For example, if you use “blue” as a search term, a search across all fields will display 28,950 records in the results list, and a search including the ARTigo tags will display 44,091 records.
Within the NFDI4Culture project, in the Task Area 3 “Research tools and data services“, the Flex Funds are available over four years to support projects and measures for the needs-based development or further development of research tools and data services in the NFDI4Culture communities.
In the first project year 2021, further developments were carried out by Task Area 3 staff, for example the image similarity search for prometheus.
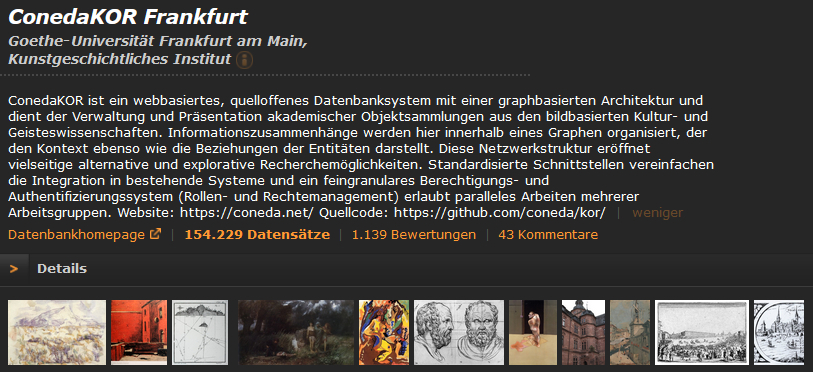
In 2022, measures proposed for funding by the first Community Forum were funded, including the documentation and optimization of the open source graph database system ConedaKor.
After the second Community Forum, funding totaling €120,000 was approved in consultation with the Culture Steering Board, including the further development of the Graphical User Interface of the Corpus Vitrearum Medii Aevi and the further development of Kompakkt.
In 2024, a further ten measures were funded and applications for the fourth Community Forum “(Further) Development of Research Tools & Data Services“ are still possible until the end of August. The needs for tools, for the realization of which funds will again be available in 2025, will then be determined at the online meeting on 20 September from 9:00 a.m. to 1:00 p.m.
At prometheus you can use the simple search function to quickly and easily search for your search terms across all fields. In this one field, you have various options to narrow down or expand your search. For example, if you mark a search term with ~, the search will be “fuzzy”, i.e. words with a similar spelling will also be included in the search. If you enclose the search terms in quotation marks, the exact order of the conditions will be taken into account. You can also use the wildcards ? or * in your search.
The advanced search allows you to search in specific fields such as artist and title as well as search for combinations of different categories. A link is made here using the Boolean operators “and”, “or”, “and not”, for example “Raphael or Leonardo and not Madonna”.
Depending on your search query, it may also make sense for you to select image databases on a specific subject such as art, architectural history or archaeology and limit your search to these.
If you only want to search categories of databases, select all museum, institute or research databases.
As the 31st open access and 21st museum image database, the Getty Museum’s online collection with 196,526 data sets has been integrated into prometheus. since yesterday.
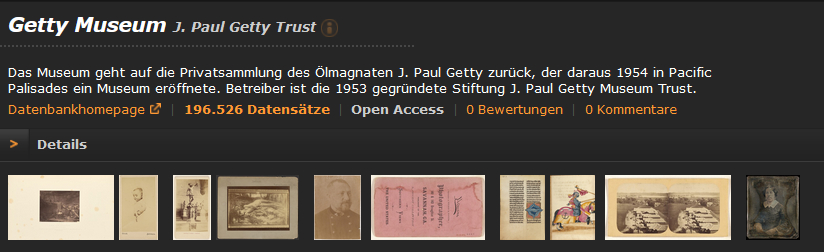
As early as in the first years of prometheus, the integration of this museum collection was a recurring topic at project meetings. When the publication of around 88,000 digital images of collection objects under the “Creative Commons Zero” (CC0) license made the rounds in March of this year, the plan was immediately up-to-date again and a new ticket was written.
Getty’s Open Content program was initiated over 10 years ago. The switch to releasing the entire public domain image collection under the CC0 license is the next step in improving transparency and access for everyone. This resource will be further expanded, including by acquiring additional works that will then be accessible to everyone for further use.
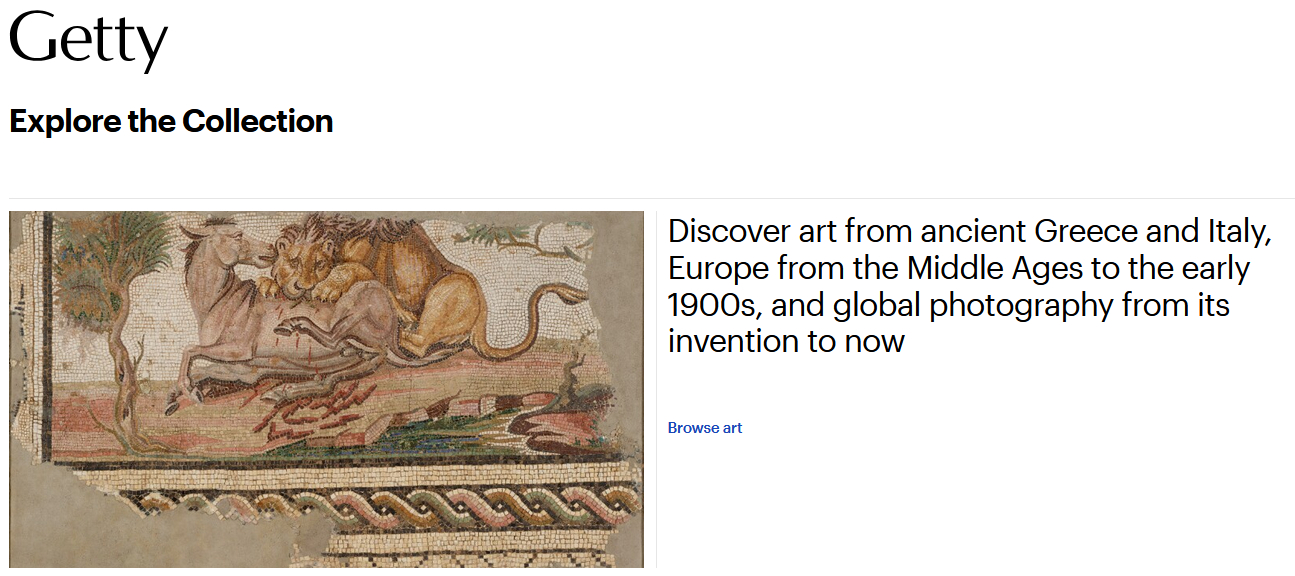
Short tip: If images are not displayed, they are not (yet?) under the CC0 license and can be viewed there and requested for further use after clicking on the original database (“house” icon in the left bar on the image).
With planning of our social media activities in the second half of the year, our next Advent calendar is of course an integral part. This year, we want to use pictures with numbers from all over the world, preferably your pictures with numbers from all over the world. We have already posted a few examples under the hashtag #prom_zahlenausallerwelt (translation: numbers from around the world).

If you are currently traveling around the world, seeing numbers, taking photos and sharing them with the hashtag, we would love to repost these photos as a story first. At the end of October, we will then raffle off some “prometheus prizes” among the participants and ask everyone via DM whether we may use the photo for the #promvent24 Advent calendar. Are you in with your photos?
You can access our Instagram account directly via the left-hand navigation bar on our homepage. In addition to the updated icons for X , Mastodon, YouTube, Instagram, Facebook and Newsletter, the NFDI4Culture Registry Badge is now also integrated there. The registry is a service of the NFDI4Culture project, which collects and records metadata about existing research tools and data services that are specifically suitable for cultural studies. It provides a simple overview and prevents duplicate developments.
Do you want to publish images that you have found in prometheus? Since prometheus itself does not own any image rights, you usually cannot obtain the necessary publication permissions directly from the image archive. However, we can help you with information about the image rights for the respective images. You will find a link to the image rights for the selected image directly on the image, in the bottom left-hand bar: §.

There you will find information about the image rights for the respective work (1.a.), the respective photo (1.b.), the image credits (2.) and the image database from which the work in the image archive originates. You will also find instructions there on how, with whom and where you can clarify the publication rights.
In some cases you will see § with an asterisk at the bottom of the left bar – §* – …
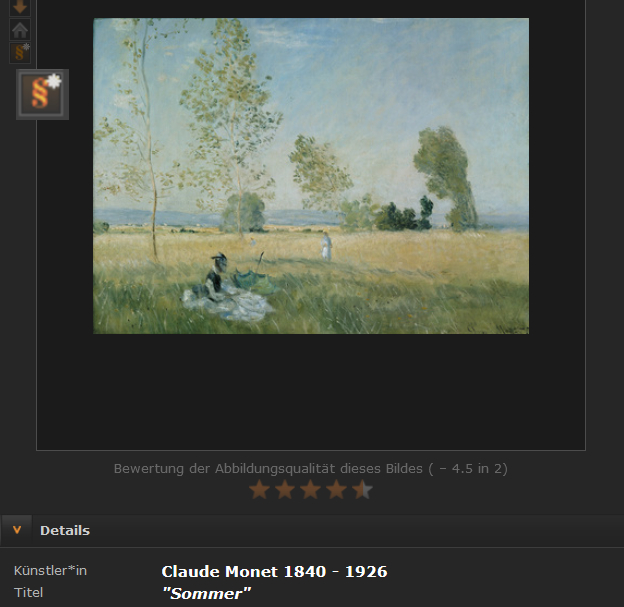
… then you can obtain publication permission via a direct link, as in this example with images from bpk – Image Portal of Art Museums, Image Agency for Art, Culture and History, Prussian Cultural Heritage Foundation, Berlin. First select the type of publication for which you intend to use this image and complete the other fields on the form. As soon as you save the information, the form will be sent and you will receive further information at the email address provided.
With the aim of using structured data for research that can be maintained by everyone in a central location, Wikidata, the free database of the Wikimedia Foundation, is integrated in various places in prometheus. If Wikidata IDs are provided by the integrated image databases, there are Wikidata search links in the image archive that you can click directly, so that you can get to the corresponding authority file in Wikidata outside of prometheus. Within the image archive, you can search directly for the Wikidata IDs and add the corresponding Wikidata ID to the artist fields of the images, thereby updating the data at the same time, as here in the case of Frei Paul Otto:
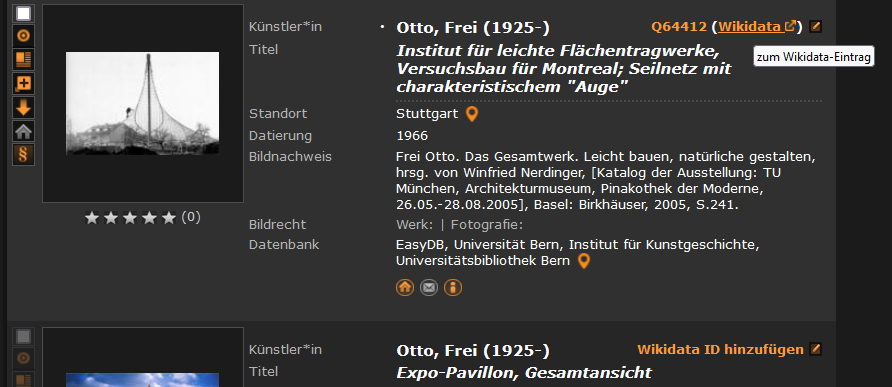
When you click on “Add Wikidata ID”, a window opens in which you can first enter the name and then select the corresponding Wikidata entry. After saving, the Wikidata ID is added as a search link. If necessary, you can click on the pen to make corrections.
So far, around 850 entries have been added in this way. We look forward to the first 1,000. :-)
Anyone who has personal access to prometheus can create image collections in the image archive. You can use these image collections privately or share them with individuals, for example to work together on a topic for a presentation. You can also publish them in readable or writable format to give everyone in prometheus access.
Another option is to download your image collections to use them further in a research or teaching context. There are two download options available to you.
(1) You can download the image collection as a zip file. If you unzip this file, you will have the images in one folder as well as text files with the corresponding metadata for each individual image.

(2) You can export the image collection as a PowerPoint file. A slide is created for each image, including the metadata title, artist, date and location. You can now edit this presentation individually for your homework or presentation.

You can also enrich your own and public image collections to create material collections. Firstly, by adding a description of the topic of the image collection or keywords such as type, genre, era or time period. Secondly, by adding literature references and web addresses, externally for content on the topic or internally for relevant image collections in the image archive. You can add further information, suggestions for discussion and research questions in the comments.

Integrated in prometheus is the Image database ‘Architecture Museum’ of the Technical University of Berlin since 2008. A lot has happened and developed over the years, not only in the digitization of further drawings, prints and photographs or the link to the The Integrated Authority File (GND) of the German National Library.
It was definitely time for an update. Instead of 26,636, there are now 161,680 data records available for your research in the field of architectural history. Many of the works and digital copies are in the public domain and the TU Berlin is happy to receive an image credit.
We hope you enjoy your research.
